분산 디버깅을 할 수 있는 방법
- 상관관계 ID를 사용해 여러 서비스 사이 트랜젝션 연결
- 여러 서비스 사이 로그 데이터를 검색가능한 단일소스로 수집
- 여러 서비스 사이 사용자 트랜잭션 흐름을 시각화 하고 특성을 이해
사용할 수 있는 세가지 기술
- 스프링 클라우드 슬루스
상관관계 ID 사용해 HTTP호출을 측정하는 스프링 클라우드 프로젝트 - 페이퍼트레일
여러 데이터소스 로그 데이터를 검색 가능항 단일 데이터서비스로 수집하는 freemium 서비스 - 집킨
여러 서비스 사이 트랜젝션 흐름 보여주는 오픈소스 기반 데이터 시각화 도구
9.1 스프링 클라우드 슬루스와 상관관계 ID
상관관계ID는 임의로 생성되는 고유한 숫자 또는 문자열로 트랜잭션을 시작할 때 주입됨.
6장에서 주울 필터를 사용해 유입되는 HTTP 요청을 검사하고 상관관계 ID가 없으면 삽입했다.
상관관계 ID가 있으면 사용자 정의 가능한 UseContext객체에 매핑함.
슬루스는 모든 코드 인프라와 복잡성을 관리
- 상관관계 ID가 없으면 생성하고 서비스 호출에 주입
- 서비스에서 나가는 호출에 대해 상관관계ID 전파를 관리해 트랜잭션의 상관관계 ID가 자동으로 나가는 호출에 추가
- 상관관계 정보를 스프링 MDC 로그에 추가해 생성된 상관관계 ID가 스프링 부트의 기본 SL4J와 로그백 구현으로 자동적으로 로깅.
- 선택적으로 서비스의 추적정보를 집킨 분산 추적 플랫폼에 전송.
1 - 라이선싱과 조직 서비스에 스프링 클라우드 슬루스 추가
라이선싱과 조직 서비스에 의존성 추가
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2 - 스프링 클라우드 슬루스의 추적 분석

슬루스는 4개의 추적 정보를 각 로그에 추가
1. 서비스 애플리케이션 이름
2. 추적 ID
3. 스팬 ID
4. 집킨에 추적 데이터 전송 여부

라이선싱 서비스와 조직서비스가 동일한 추적 ID를 공유하나 스팬 ID는 다르다.
9.2 로그 수집과 스프링 클라우드 슬루스
여러 서버사이 문제를 디버깅하려면 다음의 작업을 시도
- 여러 서버에 로그인해 각 서버의 로그를 검사.
- 로그를 파싱하고 관련 로그 항목을 식별하는 자체 질의 스크립트 작성.
- 서버에 있는 로그를 백업해야 하므로 다운된 서비스 복구 과정을 연장.
분산된 서버에서 문제 디버깅은 끔찍한 일.
로그데이터를 인덱싱하고 검색할 수 있는 중앙 수집 지점을 만들어 전체 서비스 인스턴스의 모든 로그를 실시간 스트리밍.

스프링 부트와 사용할 수 있는 로그 수집 솔루션
| 솔루션 | 구현모델 | 노트 |
| Elasticsearch Logstash Kibana |
오픈소스 상용 일반적으로 사내 구축형 |
범용검색엔진 ELK 스택을 이용한 로그수집 많은 핸즈온 지원필요 |
| Graylog | 오픈소스 상용 사내구축형 |
사내구축형으로 설계된 오픈 소스 플랫폼 |
| Splunk | 상용만지원 사내구축형과 클라우드 기반 |
오래되고 포과적 로그관리 및 수집도구 원래 사내구축형이나 이후 클라우드 제공 |
| Sumo Logic | 프리미움 상용 클라우드 기반 |
프리미움/계층형 모델 클라우드 서비스만 지원 기업용 계정으로 등록가능 |
| Papertrail | 프리미움 상용 클라우드기반 |
프리미움/계층형 가격모델 클라우드 서비스만 지원 |
1 - 스프링 클라우드 슬루스/페이퍼트레일의 실제 구현
1. 페이퍼트레일 계정을 생성, syslog 커넥터 구성
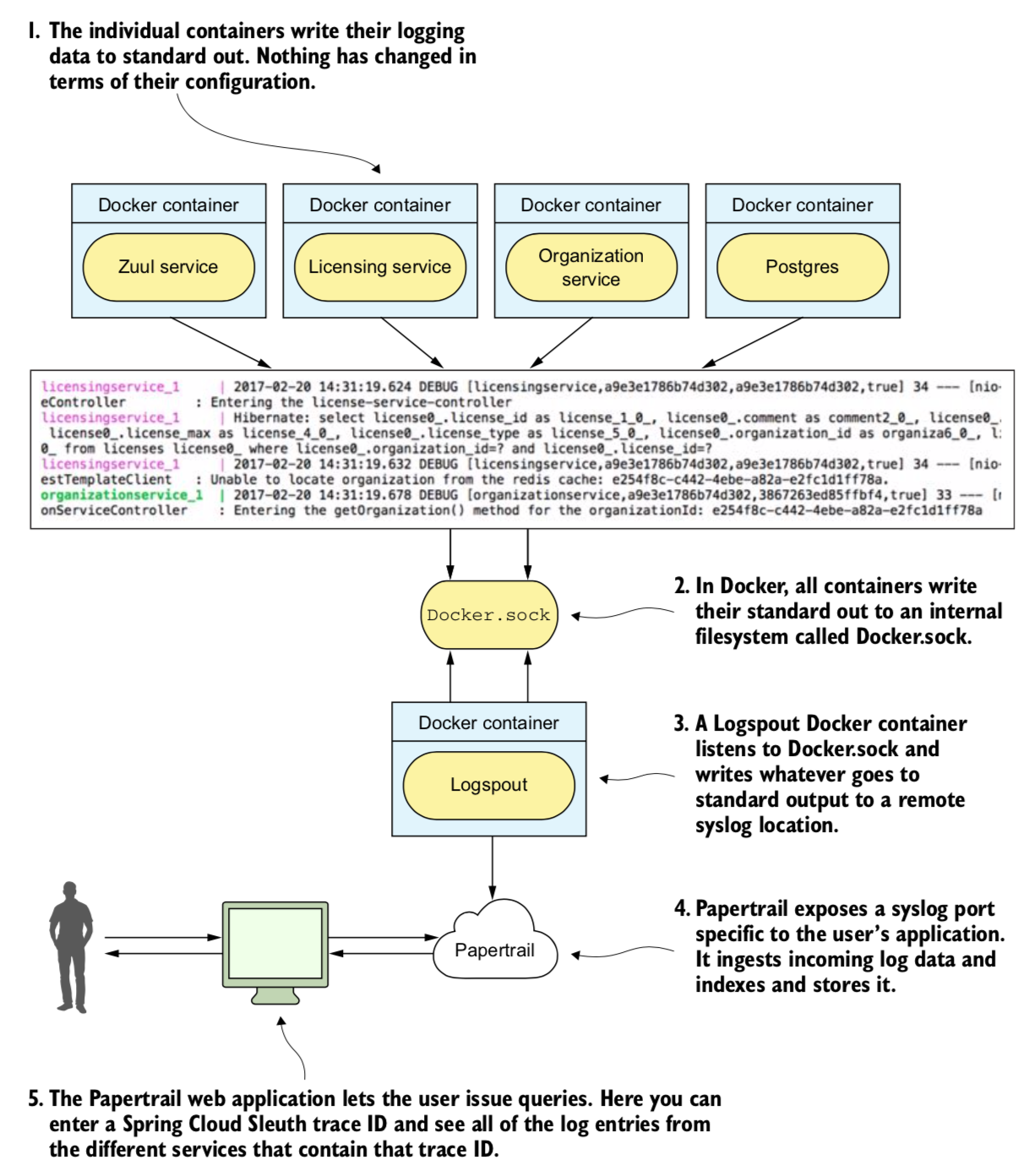
2. 모든 도커 컨테이너의 표준출력을 포착하기위해 로그스파우트 도커 컨테이너를 정의
3. 슬루스의 상관관계ID를 기반으로 질의문을 실행해 구현 테스트
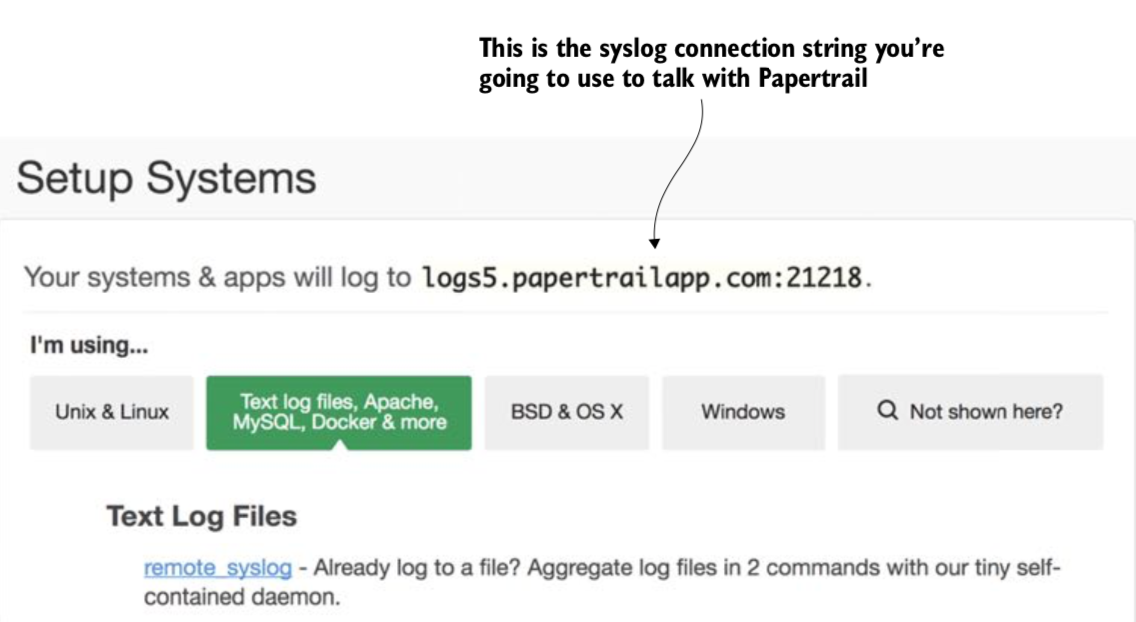
2 - 페이퍼 트레일 계정생성과 syslog 커넥터 구성
Start Logging 시작

syslog는 유닉스에서 유래한 로그 메시징 포맷으로 TCP와 UDP를 사용해 로그메시지를 보냄.

3 - 도커 출력을 페이퍼트레일로 리다이렉션
도커데몬은 관리중인 모든 도커 컨테이너와 docker.sock 이라는 유닉스 소켓으로 통신.
실행중인 컨테이너는 docker.sock에 접속할 수 있고, 해당 서버에서 실행중인 다른 컨테이너에서 생성된 모든 메시지 수신.
docker.sock은 컨테이너가 플러그인 할 수 있고,
데몬이 실행되는 가상 서버의 도커 런타임 환경안에서 수행중인 활동을 수집할 수 있는 파이프와 같다.
/docker/common/docker-compose.yml
logspout:
image: gliderlabs/logspout
command: syslog://logs5.papertrailapp.com:21218
volumes:
- /var/run/docker.sock:/var/run/docker.sock
페이퍼 트레일 Events버튼 클릭하면 볼수있는 데이터

4 - 페이퍼트레일에서 슬루스의 추적 ID 검색
한 트랜잭션과 관련된 모든 로그 항목을 쿼리하려면 페이퍼트레일에서 이벤트 화면의 추적ID로 쿼리
5 - 주울로 HTTP 응답에 상관관계 ID 추가
6장에서 주울 API 게이트웨이를 소개하며 사후 응답필터를 작성했고 서비스에서 사용하기위해 생성한 상관관계 ID를 호출자가 반환한 HTTP 응답에 추가하였는데,
이 필터를 수정해 슬루스의 헤더를 추가할 것.
주울 서버에 sleuth 의존성 추가.
주울 사후필터로 스프링 클라우드 슬루스의 추적 ID 추가
@Component
public class ResponseFilter extends ZuulFilter{
private static final int FILTER_ORDER=1;
private static final boolean SHOULD_FILTER=true;
private static final Logger logger = LoggerFactory.getLogger(ResponseFilter.class);
@Autowired
Tracer tracer; //추적ID 스팬ID 정보에 접근하는 진입점
@Override
public String filterType() {
return "post";
}
@Override
public int filterOrder() {
return FILTER_ORDER;
}
@Override
public boolean shouldFilter() {
return SHOULD_FILTER;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
ctx.getResponse().addHeader("tmx-correlation-id", tracer.getCurrentSpan().traceIdString());
//슬루스의 추적 ID를 전달하기 위해 'tmx-correlation-id' 새로운 HTTP 응답헤더 추가
return null;
}
}

9.3 오픈집킨으로 분산 추적
여러 마이크로 서비스 간 트랜잭션 흐름을 시각화
집킨은 여러 서비스 호출사이 트랜잭션을 추적하는 분산 추적 플랫폼.
서비스별 소요된 시간과 성능문제를 파악.
1 - 스프링 클라우드 슬루스와 집킨 의존성 설정
주울과 라이선싱, 조직서비스에 zipkin 의존성 추가
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>RabbitMQ나 카프카를 이용해 집킨서버 추적데이터 전송도 가능.
2 - 집킨 연결을 위한 서비스 설정
각 서비스의 application.yml 프로퍼티 파일 설정.
spring.zipkin.baseUrl 설정
3 - 집킨 서버 설치 및 구성
집킨 서버에 필요한 의존성
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>**스프링부트 2.0으로 집킨 서버를 사용자 구현하는건은 더이상 지원하지 않음.
집킨 설정이 단순하므로 @EnableZipkinServer 사용하지만
메시지큐 구성과 함께 구성하려면 @EnableSipkinStreamServer 사용.
집킨서버의 부트스트랩 클래스 작성
@SpringBootApplication
@EnableZipkinServer
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
집킨 서버에 구성할 수 있는 추적데이터 백앤드 데이터 저장소
- 인메모리 데이터
- MySQL
- 카산드라
- Elasticsearch
운영시에는 인메모리는 사용 x
4 - 추적 레벨 결정
각 서비스가 집킨에 데이터를 기록할 빈 정의
집킨의 기본설정에 따라 전체 트랜잭션의 10%만 집킨서버에 리골
트랜잭션 샘플링은 집킨으로 데이터를 전송하는 각 서비스의 스프링 프로퍼티를 설정해 제어.
sping.sleuth.sampler.percentage 0과 1 사이 값.
@Bean
public Sampler defaultSampler() { return Sampler.ALWAYS_SAMPLE; }
5 - 집킨으로 트랜잭션 추적
사용자 트랜잭션에 속한 모든 서비스와 개별 성능시간을 이해하는것은 분산 아키텍처를 지원하는데 매우 중요.
각 트랜잭션은 하나 이상의 스팬으로 나뉨. 집킨에서 스팬은 타미미이 정보가 포함된 특정 서비스나 특정 호출을 나타냄.
주울 게이트웨이는 유입되는 HTTP 호출이 있다면 그 호출을 종료한 후 대상서비스로 새로운 호출을 만들어 호출.
주울은 게이트웨이로 들어가는 개별호출에 사전, 응답, 사후 필터를 추가할 수 있다. 주울에서 스팬이 2개로 보이는 이유.



6 - 복잡한 트랜잭션 시각화
서비스 호출사이 어떤 서비스 의존성이 존재하는지 알고싶다면
주울로 라이선싱 서비스를 호출한 후 라이선싱 서비스 추적을 위해 집킨에 질의
주울 게이트웨이 호출 - 라이선싱 서비스 호출 - 주울로 다시 조직서비스 호출

7 - 메시징 추적 수집
슬루스는 서비스에 등록된 인바운드 또는 아웃바운드 메시지 채널에 대한 추적 데이터도 집킨에 전송.
슬루스와 집킨을 사용하면 메시지가 큐에 발행된 시점과 수신된 시점을 확인 가능함.
큐에 수신되고 처리될때 발생하는 동작을 확인.




8 - 사용자 정의 스팬 추가
라이선싱 서비스가 레디스를 호출할 때 사용자 정의 스팬을 추가
레디스에서 라이선싱 데이터를 읽어오는 호출 측정
@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
@Autowired
Tracer tracer;
@Autowired
OrganizationRedisRepository orgRedisRepo;
private static final Logger logger = LoggerFactory.getLogger(OrganizationRestTemplateClient.class);
private Organization checkRedisCache(String organizationId) {
Span newSpan = tracer.createSpan("readLicensingDataFromRedis");
try {
return orgRedisRepo.findOrganization(organizationId);
}
catch (Exception ex){
logger.error("Error encountered while trying to retrieve organization {} check Redis Cache. Exception {}", organizationId, ex);
return null;
}
finally {
newSpan.tag("peer.service", "redis");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}
}
}
계측이 적용된 getOrg() 메서드
@Service
public class OrganizationService {
@Autowired
private OrganizationRepository orgRepository;
@Autowired
private Tracer tracer;
@Autowired
SimpleSourceBean simpleSourceBean;
private static final Logger logger = LoggerFactory.getLogger(OrganizationService.class);
public Organization getOrg
(String organizationId) {
Span newSpan = tracer.createSpan("getOrgDBCall");
logger.debug("In the organizationService.getOrg() call");
try {
return orgRepository.findById(organizationId);
}
finally{
newSpan.tag("peer.service", "postgres");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}
}
}
2개의 사용자 정의 스팬을 적용한 후 서비스 재시작
엔드포인트 GET 호출
http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442 -4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a
라이선싱 정보를 검색할 때 추가된 사용자 정의 스팬 보여줌.
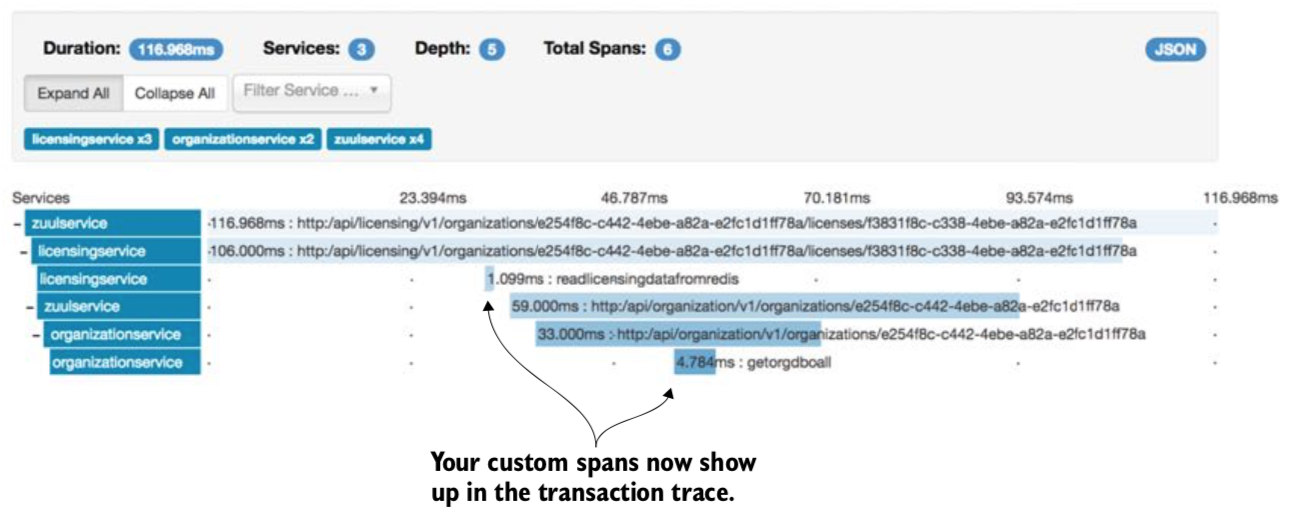
- 스프링 클라우드 슬루스를 사용해 마이크로서비스 호출에 상관관계 ID 추가
- 상관관계 ID는 여러 서비스 사이 로그 항목을 연결하는데 사용
- 로그를 수집하고 수집된 내용을 검색, 질의하는 수집 플랫폼과 상관관계 ID가 함께 함.
- 클라우드 기반 서비스 사용해 로그를 관리하면 쉽게 확장 가능
- 도커 컨테이너 로그 스파우트와 클라우드 로깅 플랫폼 페이퍼트레일 과 통합해 로그 수집
- 집킨을 사용해 서비스 호출사이 존재하는 의존성을 시각적으로 확인
- 슬루스는 집킨과 통합
- 슬루스가 활성화된 서비스에 사용되는 HTTP 호출과 메시지 채널에 대한 추적데이터 자동으로 포착
- 슬루스는 각 서비스 호출을 스팬개념에 매핑. 집킨에서 각 스팬의 성능 확인.
- 슬루스와 집킨에서 스프링기반이 아닌 지원(Postgres,레디스)의 성능을 파악하도록 사용자 정의 스팬을 재정의.
'IT Book Summary > 스프링 마이크로 서비스 코딩공작소' 카테고리의 다른 글
| Chapter 10 마이크로서비스의 배포 (0) | 2020.09.07 |
|---|---|
| Chapter 08 스프링 클라우드 스트림을 사용한 이벤트 기반 아키텍처 (0) | 2020.08.17 |
| Chapter 07 마이크로서비스의 보안 (0) | 2020.08.11 |
| Chapter 05 나쁜상황에 대비한 스프링 클라우드와 넷플릭스 히스트릭스의 클라이언트 회복성 패턴 (0) | 2020.07.27 |
| Chapter 04 서비스 디스커버리 (0) | 2020.07.23 |



